Reducing database queries to a minimum with DataLoaders

Written by Henri Normak
In our previous posts, we’ve talked about improving performance by streamlining processing and by minimising the overhead in libraries such as node-postgres, this time, let’s dive deeper into how we’ve reduced our database queries (both read as well as writes) to a minimum.
DataLoaders?
The original concept of DataLoaders, as described in the repository, came from Facebook in 2010:
… A port of the “Loader” API originally developed by @schrockn at Facebook in 2010 as a simplifying force to coalesce the sundry key-value store back-end APIs which existed at the time. At Facebook, “Loader” became one of the implementation details of the “Ent” framework, a privacy-aware data entity loading and caching layer within web server product code. This ultimately became the underpinning for Facebook’s GraphQL server implementation and type definitions.
DataLoader is a simplified version of this original idea implemented in JavaScript for Node.js services. DataLoader is often used when implementing a graphql-js service, though it is also broadly useful in other situations.
Simply put, a DataLoader is an abstraction between application code and some backing store, such as a database, allowing batching of requests, as well as caching.
The concept is heavily used in the world of GraphQL, where it is often used to remedy the N+1 problem. This is also where we first encountered this concept, on the GraphQL API that serves our frontend application.
DataLoaders in GraphQL
In our GraphQL server, we use DataLoaders to achieve effective batching and caching of database reads for each incoming request. This means for each request we build a separate set of DataLoaders, that are then discarded after the request finishes.
A simple example of how DataLoaders might come into play, given this simplified GraphQL query, returning a list of transports the current user has access to. For each transport, the respective carrier is also returned.
Assuming, for example, that the user has access to 5 transports. Without DataLoaders, we would be looking at 8 database queries:
- 1 call to fetch the user (viewer)
- 1 call to fetch company with ID 1
- 1 call to fetch the 5 transports
- 5 calls to fetch the carriers for each of the transports
In this example, the benefit comes from the companiesById DataLoader, as it groups the 5 calls for getting the carriers of the transports into a single database query, therefore, saving us from making 4 database queries.
You can imagine scaling this example to something more plausible, such as the user having access to 500 transports, with DataLoaders, the database query count is still 4, without DataLoaders, it would now be 503.
This approach helps us solve the aforementioned N+1 problem, whilst maintaining privacy by sandboxing each request to a separate set of DataLoaders — the cached results are not shared between requests, meaning any permissions logic is never shared.
The DataLoaders also avoid errors in database queries by avoiding duplication of database queries, as well as speeding up the developer experience. More often than not, there already exists a DataLoader for the entity that the code is working with.
Leveraging this, we also built a plugin for apollo-server, which we mentioned in our earlier post on how we scaled our service in 30 days. This plugin analyses the AST of the incoming GraphQL query, and fires off requests to the appropriate DataLoaders — without waiting for a response — in essence priming their caches to already have the content necessary by the time the actual GraphQL query resolution reaches the point that would call the appropriate DataLoaders.
This has worked incredibly well for us, the more heavily used DataLoaders help us avoid dozens of DB queries per request, making the API respond much faster.
Implementing DataLoaders in the context of Kafka consumers
One of our early on observations was that similar to incoming HTTP requests, our Kafka consumers were often also doing many database lookups. The way our consumers are structured is that they are handling batches of messages, within these batches, for each message some processing is done, and as a result, some data gets written to the DB, or produced to Kafka.
We noticed that often, during the processing of messages, we ended up sacrificing quite a bit of performance of batch consuming if the processing required database reads.
For example, imagine that processing messages requires us to fetch some data from the database. If we get a batch of such messages, we are limited by the number of parallel connections to the DB we have, or we are forced to process the messages sequentially altogether.
This often leads to code that first gathers some set of parameters over the batch of messages, then executes a database query with all of these to get additional data, followed by splitting up the data one more time and only then processing these messages individually.
The key observation here was that we were in essence re-implementing DataLoaders, but doing so in a difficult to read way inside of each individual consumer, of which there are many.
Once we realised that DataLoaders could help us achieve the same result, but in a much more readable fashion, we were immediately on board. With some minimal refactoring and rethinking, we came up with something much more elegant:
Here we have abstracted away the building of the DataLoaders to some utility function, allowing us to structure our code more modularly — data loading code is isolated and testable separately, whilst the message consumers can be tested with DataLoaders mocked out (i.e mocking out the database aspect).
Going global with DataLoaders in Kafka consumers
With the GraphQL use-case, DataLoaders are also useful for caching the results. When nested levels of the GraphQL query use the same DataLoader, only the outermost one actually executes the database query.
However, in the context of Kafka consumers, it is very rarely the case that the same DataLoader is called more than once with the same key during processing — the code would most likely avoid the second call altogether. This is partially due to how simple our Kafka message consumers tend to be — a simple, pure function, which does some processing in very functional ways — read data, use data in processing, store result to database and optionally produce to Kafka.
Before we continue, some background knowledge on Kafka. Kafka consists of topics, which are partitioned. These topics are written to by producers, and consumed by consumer groups. Consumer groups consists of consumer instances. One consumer instance might be consuming multiple partitions of the same topic, depending on how many consumer instances there are, versus how many partitions there are in the topic. The goal is to always have all partitions of a topic covered by a consumer group subscribed to that topic.
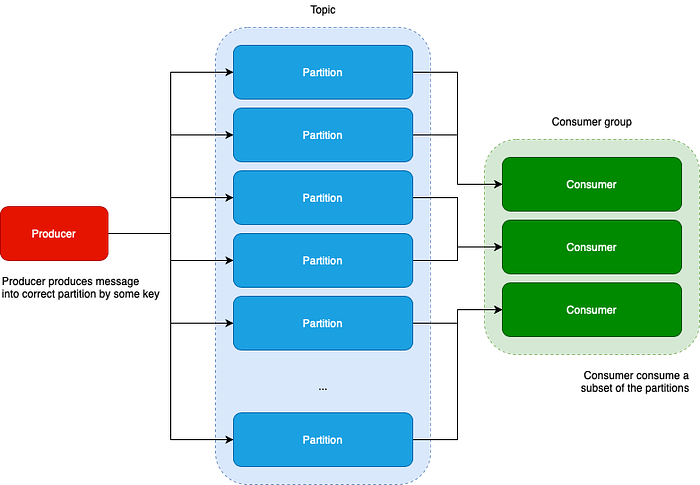
For example, we could have a topic with 100 partitions, but only 3 consumer instances in the group. This would mean that each consumer instance is handling 33(ish) partitions. Leaving aside some implementation aspects, that we might dive in deeper in some future post, in practice this means that there are N sources competing to call the consumeMessages function with batches of messages, where the N is roughly the ratio between partitions and consumer instances in the group.
This leads to an interesting opportunity, if we don’t need the caching aspect of the DataLoaders, and there are many possibly parallel callers of our message processing, could we benefit from reusing same DataLoaders across calls to our message processor? The answer is yes!
With DataLoaders that are created once, as the consumer instance starts, we can make use of them not only across messages in a single batch, but also across batches of messages that are coming from different partitions. This can drastically reduce the number of database queries we make, whilst also keeping the code in the consumers much more readable.
Taking our example from before, the new consumer looks more like this:
Given these iterations, we can analyse the code to come up with some estimates for performance:
Of course, in practice these numbers vary, however, the difference still remains in orders of magnitude. Also notice that with different approaches we have different options for scaling, with global DataLoaders, we can adjust the batch size to reduce the number of DB queries, making them bigger. Or adding additional consumers, making more DB queries, but with smaller batches.
Using DataLoaders for writes
Up to now, we’ve only looked at scenarios in which DataLoaders are used for, well, loading data. However, what about the writes to the database? Couldn’t they benefit from batching similarly to how the reads do? Of course!
The last improvement we did was indeed related to writing data to the database. To make it easier to distinguish in code, as well as in discussions, we’ve dubbed these types of DataLoaders as MicroBatchers. They are DataLoaders that often take in, as key, some more complex structure to write to the database, and then execute a batch insert/update/upsert on those keys.
Once again, this drastically improved the performance of consumers that are mostly there to consume data into the database (auxilliary ones, for example for consuming data about related entities that other calculations might need). In fact, we now have an entire subset of consumers that don’t even read from the database and just write to it via batchers.
Conclusion
With large amounts of data comes large amounts of database queries — or at least that’s what we originally thought. With DataLoaders this assumption was challenged to its core. First on the GraphQL side, where it helps improve responsiveness of the API and the user application. Later, the same learnings helped us improve performance on the Kafka consumers we have.
The key learning for us was to really embrace the concept, not only on a specific request/batch level, but by taking it global to the instance that is dealing with these requests/batches. This way we fully embrace the possibilities that parallelism offers without sacrificing the performance of our databases by flooding them with requests.
It is important to emphasise that this learning does not only apply to databases. Imagine there was a RESTful service that had some sort of rate limiting for an API. Calls to this could be abstracted into a DataLoader that takes care of the batching to stay within the limits by, for example, batching queries in time, rather than just between event loop iterations.
The possibilities DataLoaders offer are varied and can be useful in many different scenarios, it is a strong tool in our toolbelt that we can employ to make code more performant, without sacrificing readability.
